학교에서 배운지 꽤 오래 지났지만, 복습도 할 겸 기계학습 입문 수업에서 배운 내용을 포스팅 하고자 한다. 그 첫번째는, k-nn방법을 이용해 붓꽃의 품종을 분류하는 것이다.
한 식물학자가 붓꽃의 꽃잎과 꽃받침의 폭과 길이를 측정한 데이터를 바탕으로 setosa, versicolor, virginica 나눴다. 위와 같은 측정 데이터를 바탕으로 채집한 붓꽃이 어떤 품종인지 구분하는 머신러닝 모델을 만들 것이다.
붓꽃의 품종을 정확하게 분류한 데이터를 가지고 있으므로 지도학습에 속하고, setosa, versicolor,virginica 중 하나를 선택하는 것이므로 분류(classification)에 속한다.
(1) 데이터 적재
from sklearn.datasets import load_iris
iris_dataset=load_iris()
load_iris가 반환한 것은 키와 값으로 구성된 dictionary이다. iris_dataset으로 load_iris를 받고, iris_dataset의 키가 어떤 것이 있는지 알아보자.
print("iris_dataset의 키:\n", iris_dataset.keys())
out
iris_dataset의 키:
dict_keys(['data', 'target', 'target_names', 'DESCR', 'feature_names', 'filename'])
다음과 같이 iris_dateset의 키를 출력할 수 있다. 이 중 DESCR가 어떻게 구성되어 있는지 알아보자.
print(iris_dataset['DESCR'][:193]+"\n...")
out
.. _iris_dataset:
Iris plants dataset
**Data Set Characteristics:**
:Number of Instances: 150 (50 in each of three classes)
:Number of Attributes: 4 numeric, pre
...
다음으로는 target_names을 출력해보자
print("타깃의 이름:", iris_dataset['target_names'])
out
타깃의 이름: ['setosa' 'versicolor' 'virginica']
우리가 예측해야하는 세 종의 이름이 target_names에 문자열 배열로 들어있다. setosa=0, versicolor=1, virginica=2로 실제로 저장은 인덱스로 한다.
다음은 feature_names에 대해 알아보겠다.
print("특징의 이름:\n", iris_dataset['feature_names'])
out
특징의 이름:
['sepal length (cm)', 'sepal width (cm)', 'petal length (cm)', 'petal width (cm)']
feature_names는 각 특성을 설명하는 문자열 리스트이다. 우리는 이를 통해 iris 데이터는 4차원 feature를 갖는 데이터임을 알 수 있다.
다음으로는 data의 타입을 알아보자.
print("data의 타입:", type(iris_dataset['data']))
out
data의 타입: <class 'numpy.ndarray'>
data는 꽃잎의 길이와 폭, 꽃받침의 길이와 폭을 수치 값으로 갖는 numpy 배열임을 알 수 있다.
다음으로 data와 target_names의 크기를 알아보겠다.
print("data의 크기:",iris_dataset['data'].shape)
print("target_names의 크기:",iris_dataset['target_names'].shape)
out
data의 크기: (150, 4)
target_names의 크기: (3,)
data를 예시로 설명하자면, data배열은 150개의 붓꽃 데이터를 가지고 있다. 이때, 머신러닝에서 각 아이템을 sample이라 하고 속성은 특성이라 하는데, data배열의 크기는 샘플의 수에 특성의 수를 곱한 값이 된다. 따라서, 150은 샘플의 개수를 의미하고, 4는 차원에 대한 설명이고, 150행에 4열을 의미한다.
이에 data의 처음 다섯 행을 출력해보자.
print("data의 처음 다섯 행:\n",iris_dataset['data'][:5])
out
data의 처음 다섯 행:
[[5.1 3.5 1.4 0.2]
[4.9 3. 1.4 0.2]
[4.7 3.2 1.3 0.2]
[4.6 3.1 1.5 0.2]
[5. 3.6 1.4 0.2]]
위 데이터로부터 다섯 붓꽃의 꽃잎 폭은 모두 0.2cm이고, 첫 번째 꽃이 가장 긴 5.1cm의 꽃받침을 가졌음을 알 수 있다.
다음은 target에 대해 알아보겠다.
print("target의 타입:",type(iris_dataset['target']))
out
target의 타입: <class 'numpy.ndarray'>
print("target의 크기:",iris_dataset['target'].shape)
out
target의 크기: (150,)
target은 위의 out을 보면 알겠지만, 각 원소가 붓꽃 하나에 해당하는 1차원 배열이다. 붓꽃의 종류는 0에서 2까지의 정수로 기록되어 있으며 위에서 언급했듯이 setosa는 0, versicolor는 1, virginica는 2이다.
print("타깃:\n",iris_dataset['target'])
out
타깃:
[0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0
0 0 0 0 0 0 0 0 0 0 0 0 0 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1
1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 2 2 2 2 2 2 2 2 2 2 2
2 2 2 2 2 2 2 2 2 2 2 2 2 2 2 2 2 2 2 2 2 2 2 2 2 2 2 2 2 2 2 2 2 2 2 2 2
2 2]
target의 150개의 데이터를 출력한 것이다. 각 클래스마다 50개의 데이터가 있다. (setoasa 50개, versicolor 50개, virginica 50개)
## (2) 성과 측정:훈련데이터와 테스트 데이터
from sklearn.model_selection import train_test_split
#train:test=0.75:0.25
x_train,x_test,y_train,y_test=train_test_split(iris_dataset['data'],iris_dataset['target'],random_state=0)
train_test_split 함수를 이용헤 데이터셋을 train과 test셋으로 나눠주는데 그 전에 유사 난수 생성기를 사용해 데이터셋을 무작위로 섞어준다. 이는 print("타깃:\n",iris_dataset['target'])출력을 확인하면 알 수 있듯이, 데이터가 순서대로 정렬되어 있기 때문이다. 3개의 클래스 중 하나만 포함한 test셋을 이용하면 모델이 얼마나 잘 일반화되는지 확인하기 어렵기 때문에, test셋이 세 클래스의 데이터를 모두 갖도록 섞어준다.
print("x_train의 크기:",x_train.shape)
print("y_train의 크기:",y_train.shape)
out
x_train의 크기: (112, 4)
y_train의 크기: (112,)
print("x_test의 크기:",x_test.shape)
print("y_test의 크기:",y_test.shape)
out
x_test의 크기: (38, 4)
y_test의 크기: (38,)
(3) 데이터 살펴보기
머신러닝 모델을 만들기 전 필요한 정보가 누락되지는 않았는지 데이터를 조사해보는 것이 좋다. 또한, 데이터에 일관성이 없거나 이상한 값이 들어가 있는 경우가 종종 있기 때문에 시각화와 같이 데이터를 조사하는 것은 아주 좋은 방법이다.
이 포스팅에서는 산점도를 이용해 데이터를 조사할 것이다.
import pandas as pd
from preamble import *
#x_train 데이터를 사용해서 데이터 프레임을 만든다.
#열의 이름은 iris_dataset.feature_names에 있는 문자열을 사용한다.
iris_dataframe=pd.DataFrame(x_train,columns=iris_dataset.feature_names)
#데이터프레임을 사용해 y_train에 따라 색으로 구분된 산점도 행렬을 만든다
pd.plotting.scatter_matrix(iris_dataframe,c=y_train, figsize=(15,15),marker="o",
hist_kwds={'bins':20},s=60,alpha=.8,cmap=mglearn.cm3)
#bins:20 -> 히스토그램을 20개 만들어라.
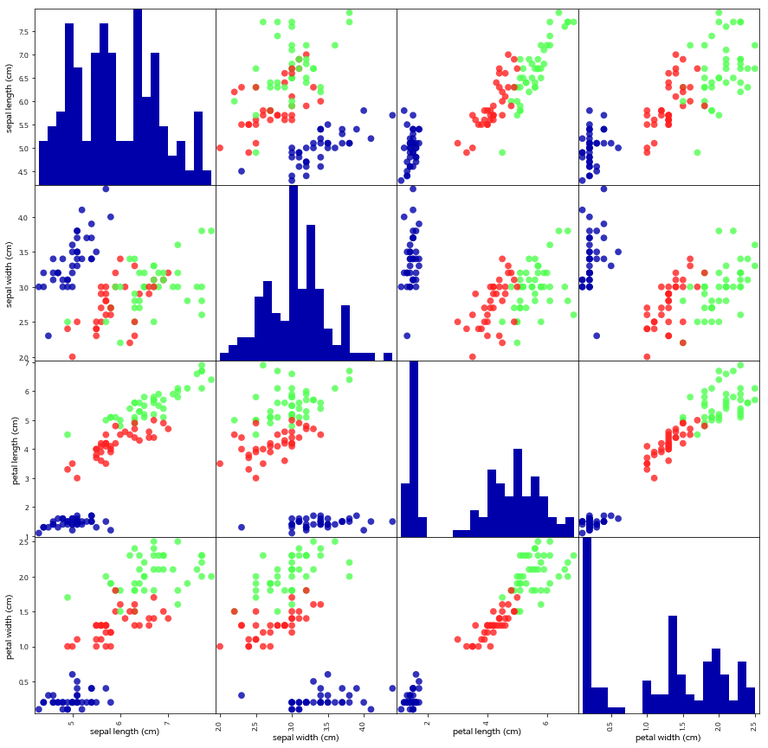
다음과 같이 우리가 가진 train 데이터를 볼 수 있다. 그러나 원래는 4차원 데이터는 표시할 수 없다. 그럴 때, 쓰는 것이 바로 이 산점도 행렬이다. 대각선에 있는 것들은 빈도수를 나타내는 히스토그램으로 대각선 이외의 것을 보면 된다. 다음과 같이 빨간색, 파란색, 녹색끼리 잘 모아져 있으므로 잘 나눠져 있는 좋은 데이터임을 알 수 있다.
(4) 첫번째 머신러닝 모델: K-최근접 이웃 알고리즘
KNN은 가장 이해하기 쉬원 분류기이다. 이 모델은 단순히 훈련데이터를 저장하여 만들어진다. 새로운 데이터에 대한 예측이 필요하면 알고리즘은 새 데이터에서 가장 가까운 훈련 데이터를 찾는다. 그리고 찾은 훈련 데이터의 레이블을 새 데이터의 레이블로 지정한다. scikit-learn의 모든 머신러닝 모델은 estimator라는 파이썬 클래스로 각각 구현되어 있으며, k-최근접 이웃 분류 알고리즘은 KNeighborsClassifier에 구현되어 있다. 이때 모델에 필요한 매개변수를 넣습니다. KNeighborsClassifier에서 가장 중요한 매개변수는 이웃의 개수인데 여기선 1로 지정해보겠다.
from sklearn.neighbors import KNeighborsClassifier
knn=KNeighborsClassifier(n_neighbors=1) #knn적용하는 법
knn.fit(x_train,y_train)
out
KNeighborsClassifier(algorithm='auto', leaf_size=30, metric='minkowski',
metric_params=None, n_jobs=None, n_neighbors=1, p=2,
weights='uniform')
fit은 훈련 데이터세트로부터 모델을 만들 때 사용한다.
(5) 예측 및 모델 평가하기
x_new=np.array([[5,2.9,1,0.2]])
print("x_new.shape:",x_new.shape)
out
x_new.shape: (1, 4)
knn 객체의 predict메서드를 이용해 예측을 한다.
prediction=knn.predict(x_new)
print("예측:",prediction)
print("예측된 타깃의 이름:",iris_dataset['target_names'][prediction])
out
예측: [0]
예측된 타깃의 이름: ['setosa']
이 모델은 setosa로 예측을 했다. 이제 이 결과를 신뢰할 수 있는지 모델을 평가해보도록 하겠다. 성능을 평가하는 방법은 테세트 데이터에 있는 붓꽃의 품종을 예측하고 실제 레이블과 비교하는 것이다. 얼마나 많이 맞았는지 정확도를 계산하는 방법으로 모델의 성능을 평가한다.
y_pred=knn.predict(x_test)
print("테스트 세트에 대한 예측값:\n",y_pred)
out
테스트 세트에 대한 예측값:
[2 1 0 2 0 2 0 1 1 1 2 1 1 1 1 0 1 1 0 0 2 1 0 0 2 0 0 1 1 0 2 1 0 2 2 1 0
2]
print("테스트 세트의 정확도: {:.2f}".format(np.mean(y_pred==y_test)))
out
테스트 세트의 정확도: 0.97
이 외에도 score메서드를 통해서도 정확도를 계산할 수 있다.
print("테스트 세트의 정확도: {:.2f}".format(knn.score(x_test,y_test)))
out
테스트 세트의 정확도: 0.97
정답률이 높을수록 1에 가까운 정확도가 출력된다.
## (6) 요약
사실 우리가 위에서 길게 작성한 코드는 이 한블록으로 끝난다.
x_train, x_test, y_train, y_test=train_test_split(iris_dataset['data'],
iris_dataset['target'],random_state=0)
knn=KNeighborsClassifier(n_neighbors=1)
knn.fit(x_train,y_train)
print("테스트 세트의 정확도: {:.2f}".format(knn.score(x_test,y_test)))
out
테스트 세트의 정확도: 0.97